
Is "Web 3" Really "Web 3"?
Is "Web 3" Really "Web 3"?
The road to digital emancipation

I am concerned and confused about the web3 space. My feelings are the same as those of many: is web3 really web3? I think the first step in answering that is to agree upon a shared definition of web3. I’ve been trying to figure out exactly how to do that when I came across this 2005 article written by Tim O’Reilly titled “What is Web 2.0”. In it, he identified 7 key principles of Web 2.0.
Platform not a service.
Collective intelligence.
Proprietary data.
End of the software release cycle.
Lightweight programming models.
Software that is not limited to a single device.
Rich UX.
You can comb through all the fine details in the article itself, but the point here is that this piece has convinced me that we need to start developing something similar with respect to web3.
As part of an initial attempt, I’ve been asking myself: what does it mean for a platform to be web3 and “fully decentralized”? Here are just a few things that I’ve identified as important to me. My list may change and you may have your own list.
Open borders.
Data portability and platform independence.
Censorship resistance.
Profit share skewed towards creators.
I intentionally left out things like “uses blockchain”, “mintable NFTs”, “tokenomics”, “creator coins”, and the like. I don’t think that the use of this particular technology is an effective gauge of what is web3 and what isn’t. In fact, because we’ve made that mistake over the last several years is one of the reasons why it has become so damn hard to figure out how to tease apart the principles from the tech. These buzzwords have in many ways become a Trojan Horse for web2 paradigms that cypherpunk enthusiasts want to leave behind. Some of those words, like “tokenomics” and “creator coins”, often mean nothing and introduce complexity that disorients users too much. We need to find a set of principles that is tech agnostic like the set of principles O’Reilly defined above. In other words, just because a platform uses a ledger or lets people mint NFTs doesn’t make it web3.
Now that I had a rough draft of the list, I wanted to start testing it against existing companies in the ecosystem. I decided to start with the music web3 space, which is unsurprising if you know me.
The first platform that stuck out was naturally Audius, a streaming service whose tagline on Twitter reads as follows: “Audius is a fully decentralized music platform. Own the masters & the platform”. This seemed like as good a place as any to start.
So, for the remainder of this piece, I’ll walk through how I try to answer whether a platform matches the requirements that I listed by using Audius as an example.
Starting with…
Open Borders
Audius surely has open borders - anyone can sign up.
Though I’ll note: it's very strange that when you try to sign up with Audius, you have the option to sign up with MetaMask yet the site tells you it’s not recommended.

Of course, you can always just link your MetaMask wallet once you log in.

There’s a meme here but I just can’t put my finger on it ;)



Jokes aside, I am actually very excited by decentralized IDs and universal login. The DID community and W3C have been doing some really interesting work around defining standards for how these things should operate. There are even some web3 projects that are incorporating these standards - like Ocean Protocol and TBL’s Solid Project. Plenty of fascinating things happening in web3 but the bulk of that work is not in any consumer facing enterprise in my opinion.
Regardless, I hope we can share a laugh. Life’s too short.
Data Portability and Platform Independence
What does data portability mean on a music streaming platform? I should be able to upload a song using the platform and still be able to access that song from another platform. The song does not belong to the platform I upload through, and it should not be locked into the platform’s database. The platform should simply provide the software that allows me to upload to a system like IPFS.
Does Audius allow for data portability? Given the past three day weekend, I had some time on my hands to try and answer this. What I did was first look at the network requests that were being made from my browser when I was streaming songs on Audius. I found URLs that looked like the ones shown in the image below.
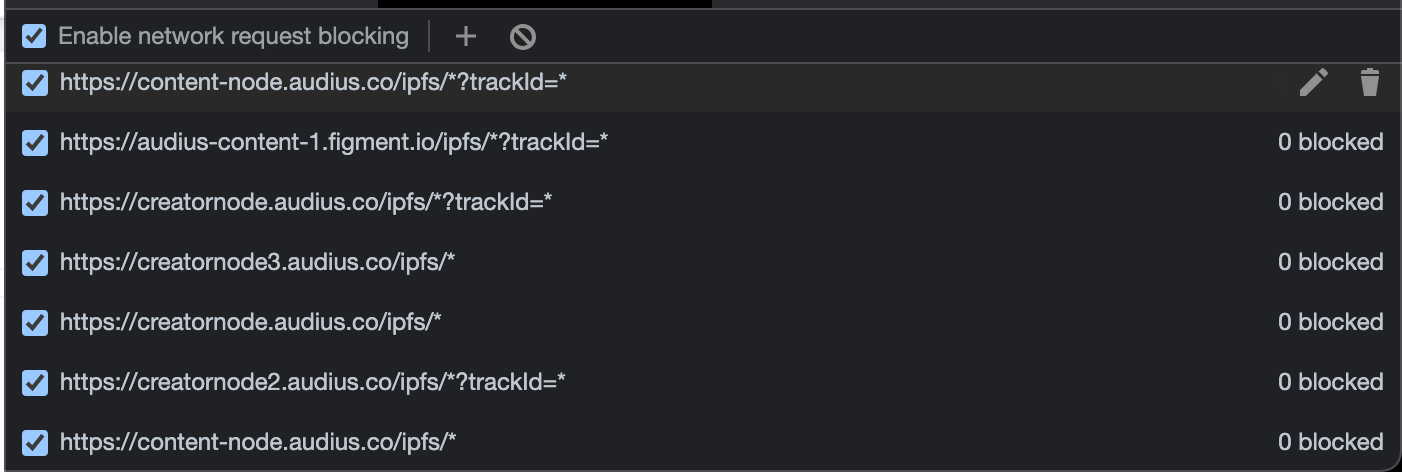
I’m guessing that many of these are IPFS gateways that Audius is hosting themselves. I then decided to block all these network requests so that my browser wouldn’t be able to talk to those servers in order to get data. I only had to block the ones shown in the image above and all the songs would stop playing after 5 seconds. My guess is that this is because Audius only sends us the first 5 seconds of the audio from a URL that looks like blob:https://audius.co/* and requests the rest of the data from those IPFS gateway nodes listed above. As of 1/19/22 there are a total of 32 Audius content nodes that serve the content and they are all listed here.
I eventually found some insight into what is happening and admittedly, I am positively surprised by the relatively transparent info on how some of their systems work. In this blog post, Audius explains what happens when an artist uploads a track.

When you upload a track to Audius it gets saved and duplicated across a total of 3 computers referenced here as “Content Nodes”. These are the content nodes that I mentioned previously. All of these content nodes run the Audius protocol. Seems like the code is open-sourced here under their main repository.
Then we have something called “Discovery Nodes” which can all be seen in this list here. There are a total of 37 as of 1/19/22. Once the track is uploaded and duplicated across the content nodes, all the locations of where that track has been duplicated is saved onto a discovery node. The discovery nodes are basically phone books or directories that tell us where to look for the songs.
Lastly, we have an “onchain transaction” that says “the track exists on Audius”. Honestly, I’m not sure where this transaction is happening or who is signing it. When I uploaded a track to Audius I didn’t sign anything nor did I need to have a cryptowallet connected. I thought maybe I had done something wrong so I went back, connected my wallet, and uploaded another track. No difference. My educated guess would be that the content nodes are signing the transaction which makes sense given where the signing happens in that described flow. Although, it would be nice to have some more visibility into this process on the user side of things.
Most users will not know anything about this process because (1) it can be technically convoluted and (2) it’s not explained anywhere well except in a blog post which itself is not very clear. For instance, once I upload a song I’d like to see the transaction hash and be able to cross-reference it on Etherscan myself. I may even want to sign that transaction myself if that signature is important to prove that I own the song, or at the very least that I am the one who uploaded it.
I also never got back the CID (content ID) for my upload. Why should I care about the CID? Well, if my track was uploaded to IPFS then I should be able to use the IPFS CID hash to access it using a public gateway like https://cloudflare-ipfs.com/ipfs/ or https://ipfs.io/ipfs/. You can take the CID hash and add it to the end of those URLs to access a file. I parsed through all the network requests that were happening to find hashes for various songs. I tested them against the public IPFS gateways and was unable to get any data back. The request would just end in a gateway timeout which makes me think either:
the file doesn’t exist
the node hosting the file is offline
the node hosting the file is behind a closed NAT/firewall
this hash isn’t the same hash as what it might be on IPFS
the file isn’t saved in IPFS
I’m not a DevOps/network engineer so maybe a more experienced DevOps/network engineer will be able to explain this in more detail, but my educated guess is that the songs uploaded to Audius aren’t actually stored on IPFS. The file definitely exists - I can access it through Audius. The node is definitely online for the same reasons. The fourth possibility seems odd if true - not sure why there would be that level of complexity where a hash references a hash. One hash seems like it would be enough and easier to keep track of, but I’ll always leave room for doubt that I misunderstood something here. From the IPFS blog about Audius it seems like what they are saying is that Audius runs an internal IPFS network which is in effect a private network. However, in Audius’s own ToS, they mention that songs get uploaded to IPFS and are accessible by public gateways, which is the opposite of what I found. Despite the documentation being incongruent, I think the third and fifth options are the most probable given what we know.
At this point I was thinking that maybe I had done something wrong still and made some incorrect assumptions about how IPFS worked. So I decided to get some quick practice with it. Turns out that uploading files to IPFS is super easy if you know how to use a CLI. I did a quick crash course, read a bunch of docs, and asked some questions to the IPFS dev help team. I learned that you can use the CLI command ipfs dht findprovs <CID> to check which nodes are hosting the provided CID. I tried running that command with several CIDs that I parsed from the network requests earlier. No results, which apparently means that the file is not on IPFS according to the IPFS dev support. The other possibility is if the file was not stored in DHT and instead in a 3rd party cloud hosting service like Pinata (which is analogous to AWS S3).
In order to check this, I would have to manually connect to one of these providers in order to search and/or download through their files. I am yet to confirm whether this is the case or not, mostly because this felt like an interesting but unreasonable rabbit hole to go down. Instead, I briefly combed through their public repository for references to Pinata. The most interesting references are here and here, both of which are effectively the same piece of code - one in the client side and one in the server side code. As far as I can tell, this code is not pinning/saving any interesting or useful content. It looks more like it is pinning a reference to IPFS addresses of content nodes. I even tried taking a wild guess by navigating to:
https://gateway.pinata.cloud/ipfs/QmXSa6NxfA3e2hCpd8P5gNnZJs9PjZ3yGDHiRHR5B7Rq52/QmTMU4z3wiWysPQs5jWVNhWhz7t2a6LXvptP1pyaSWCfT3I thought that maybe I needed to tell the public Pinata gateway to reference this pinned content node address and then look for the specific CID that follows at the end. Didn’t work - you can try that link for yourself.
In short, I don’t think Audius is using something like Pinata to save the actual song data, but rather using Pinata to direct request traffic to the content nodes which host the data. I am yet to figure out how exactly I might be able to access this content publicly on my own, from a different platform, or if that is even possible. Ideally there would be an Audius blog post or documentation that tells us how to do this in the spirit of full decentralization. In any case, this has already proven to be quite involved.
From my understanding, it seems that the most likely possibility is that Audius is managing its own distributed file storage protocol (AudSP), which may or may not be on IPFS. With that said, I can see their code making use of IPFS, but the way it is setup prevents any public access. This doesn’t sound very decentralized if the network can only be accessed from within the Audius browser or app. In some ways, it feels like a permissioned ledger behind a private network. Of course since the code is open source, you could try to run your own discovery node and content node to see if you can access those files. Just make sure you have enough $AUDIO to stake to run those nodes which is quite the uphill battle in and of itself - see $AUDIO token distribution by addresses (top 100 addresses hold 96.94% of $AUDIO tokens).

Note: I haven’t yet tried running either type of node without staking just to see if I could even access the network. However, I have tried running the Audius client that allows me to run a local version of https://audius.co, which made me think. Maybe what Audius is trying to do is be the main layer on top of which music dApps are built. Since Audius itself is built on top of Ethereum (and POA), these dApps would be L3 funneled through a centralized L2, kind of like in an application-specific blockchain. This is just speculation on my part.
However, since the Audius client is open source, someone could easily take that client and repackage it so that it writes to the main ledger with user approval, makes protocol and data transparency a priority, and puts ownership and empowerment back into the users’ hands.
I’ll leave the unresolved questions as part of some future exploration that you, as the reader, might want to try digging into.
So does Audius currently meet the expectation of data portability and platform independence?
Well, let’s go through some scenarios.
If one day I decide that I want to leave Audius and move to a different platform, can I still take my songs and data with me? Given that I never got a CID for my songs and that I can’t access them using a public gateway or a different platform, doesn’t look like it. I also didn’t have to sign that upload so I’m not entirely sure what ownership means here, though there might be some answer to that in the Audius ToS.
Ok, let’s say I want to stay on Audius but maybe I want to build or use another platform that analyzes my data or does something different with my songs. Can I look up those songs using a different platform not on Audius? Again, given that I have no way of accessing that data unless I’m doing it through the Audius portal, then no.
Ok, but you said the client code was open source so anyone can take it and build on top of it. Yup, and I think this is one of the positives I noticed when digging into this. Of course, the problem still exists that if someone wanted to build a completely different platform not forked from Audius, then the songs that get uploaded into the original Audius platform won’t be accessible outside of that network even though it might be using IPFS and Ethereum underneath. That’s still a problem and forces developers to have to build off of Audius’s protocols. There is clearly a platform dependency here.
I think it’s evident to me that this system is neither data portable nor platform independent. I’m not so sure it qualifies as “fully decentralized”. It makes me feel like I’m locked in to the platform which is very reminiscent of cellphone provider contracts. This locking in and proprietary data/network (see #3 from O’Reilly’s Web 2.0 list up top) is what a web2 platform does and the ethos of web3 is to move away from that; especially given the momentum and possibilities we have here today.
Censorship Resistance
For a platform to be censorship resistant, my data needs to be fully portable and platform independent. Now this might seem redundant to add as a separate principle given that it depends on the one above; but to me this is such an incredibly important consequence of data portability that I think it deserves to be highlighted. Since my data is not fully portable or platform independent, Audius, as it is right now, is not censorship resistant.
Profit Share
I think this one is self evident. Artists currently can’t earn from streams on the platform. In order to afford doing this, Audius would probably need to figure out a clear monetization strategy. However artists can earn money from Audius by participating in and winning contests that reward you in $AUDIO, which you can then sell on a secondary market. The current rewards for winning a competition are 100 $AUDIO and the current market price for 1 $AUDIO is $1.32. The platform does try to incentivize artists to keep their $AUDIO on the platform by providing rewards back through VIP tier programs.

Closing Thoughts
So, let’s review.
Open borders.
Data portability and platform independence.Censorship resistance.Profit share skewed towards creators.
It seems that Audius would be better classified as a web2 platform rather than a web3 platform given the above. I personally don't think there's anything wrong with Audius being a web2 platform. The market could always use the competition. Spotify has in many ways felt like it has grown stale with limited innovation. Soundcloud as well. Maybe this is the market pressure all players need in order for there to be some tangible positive changes in favor of creators.
A major gripe that I’m sure many of us share is that it feels disingenuous to smuggle web2 under web3 branding when much of the core of web3 principles are missing, whether intentionally or unintentionally; because honestly, decentralization is hard af and development teams have to make tradeoffs at various junctures. Ultimately, there should be more transparency afforded to the everyday user who may not have the tech literacy needed for excavating like we just did in this piece on their own; and they shouldn't have to.
If you're pitching yourself as a web3 or fully decentralized platform in order to differentiate yourself from the old guard, you can't also hypocritically be like old guard in practice. Can't have it both ways. The real test of value to me is the following:

And as Aaron Levie said:

Maybe it’s a good idea to add “fully decentralized” to that list of forbidden words as well.
Or at the very least, have ready a list of Web 3.0 principles so that “the next time a company claims that it's "[Web 3.0]," test their features against the list above. The more points they score, the more they are worthy of the name. Remember, though, that excellence in one area may be more telling than some small steps in all.” (O’Reilly 2005)
- CRITIQ
Just as a seemingly minor invention like barbed wire made possible the fencing-off of vast ranches and farms, so too will the seemingly minor discovery out of an arcane branch of mathematics come to be the wire clippers which dismantle the barbed wire around intellectual property.
Passing thoughts:
Maybe you read this and thought, ok this guy is an idiot. It’s possible. I hope you come up with a better list and run a similar if not better or different analysis. If you do, I’d want to know about it → @therealcritiq
Where do the following key characteristics fall in this list of web3 principles?
Anonymity. Is this necessary for all web3 platforms? What about those that could benefit from KYC to improve UX, user safety, and paradoxically privacy?
Open source. Is it necessary for all web3 platforms to be transparent and open source?
Your list
Given my explorations above, I have some thoughts and speculations around what I expect Audius’s monetization strategy to be which I hope to share either in another blog or online
Some fun links (all of which are publicly available if you know where you look):
Public Gateway Checker: Here you can see a list of all IPFS public gateway nodes. If I had a few more hours and energy to spare, I would cross reference these nodes with the list of Audius content/discovery nodes; but I don’t expect to find a match. I think the Audius content/discovery nodes just serve the Audius network and not the global IPFS network. If I’m wrong, then I definitely want to know → @therealcritiq
Governance on Audius: Here you can see a list of past governance issues. Most are dev issues like upgrading software versions on nodes. There’s also something called the Audius Grants Committee.
Audius Privacy Policy: the section titled “Information on Blockchain Networks” gives some info on what is stored on-chain; although after our investigation above it’s unclear to me how exactly to view any of these transactions.
Audius Whitepaper: Section 4 titled “Content Ledger” outlines their vision for what they want to build. There are some claims in there on what the platform provides today that are inaccurate from my assessment. Interesting read nonetheless. It also partially confirms my hypothesis that AudSP is intended to be the layer upon which other music dApps should build. Section 5 on “Discovery Node” is particularly curious as well.
This link seems to give back the IPFS JSON configuration for Audius’s hosting gateway. I got that link from this line in Audius’s open sourced protocol code.
If you’re wondering where I got
https://gateway.pinata.cloud/ipfs/QmXSa6NxfA3e2hCpd8P5gNnZJs9PjZ3yGDHiRHR5B7Rq52/QmTMU4z3wiWysPQs5jWVNhWhz7t2a6LXvptP1pyaSWCfT3from, see here. If you make aGETrequest to that URL in the code, you’ll get back a CID which is what I appended to the public Pinata gateway URL. The last CID is a CID of a chunk of a song that I parsed from network requests from the Audius portal.
Credit
Thumbnail image taken without permission from Mach37.